
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- 코테
- DFS
- 그리디알고리즘
- Datastructure
- 큐
- Baekjoon
- 너비우선탐색
- 코딩테스트
- 백준
- 정렬
- 프로그래머스
- 파이썬
- 그래프탐색
- 자료구조
- 깊이우선탐색
- 데이터마이닝
- solvedac
- DP알고리즘
- 그래프
- 수학
- 반복문
- dp
- BFS
- 문제풀이
- 다이나믹프로그래밍
- greedy
- 문자열
- 그리디
- PYTHON
- 알고리즘
Archives
- Today
- Total
nyunu
[데이터 마이닝] 앙상블 (ensemble) - 기본 개념 본문
728x90
강의 출처) 2023-1 숙명여자대학교 소프트웨어학부 강의 "데이터마이닝및분석", 이기용 교수님
앙상블이란 ?
: 여러 개 분류기의 예측 결과를 합쳐서 분류 정확도를 높이는 기술
1. 기본 아이디어

(1) Training data로부터 base classifier을 조합을 형성하고
(2) 각 base classifier로부터 만들어진 예측을 가지고 투표를 진행해 결과를 냄
※ 주의사항
- 각 base classifier의 정확도는 50% 이상이어야 함
-> 정확도가 낮은 모델끼리 모아놓으면 오히려 정확도가 더 떨어지는 효과 . . . - 각 base classifier는 독립적이어야 함
- 독립적이면 base classifier 중 절반 이상이 잘못 예측해야만 오분류가 발생
-> 그러니까 정확도를 높일 수 있는 것 !! - cf) 독립적이지 않으면 ?
-> 모든 base classifier가 같은 실수를 하니까 정확도 개선이 안 됨
- 독립적이면 base classifier 중 절반 이상이 잘못 예측해야만 오분류가 발생
- 각 basie classifier는 높은 variance와 낮은 bias를 가져야 함
2. Bias & Variance란 ?

왼쪽 : high boas & low variance / 오른쪽 : low bias & high variance
(1) Bias
: 예측값의 평균과 실제값 평균의 차이
- 단순한 결정경계를 가진 모델일수록 높은 bias를 가짐
ex. logistic regression - bias가 높은 모델을 선택하면 언더피팅될 가능성이 높음
- 모델이 너무 심플해서 발생하는 문제는 해결이 불가능
(2) Variance
: 훈련 세트의 사소한 변화에 대응하는 모델의 예측의 안정성 & 예측값끼리의 차이
- 복잡한 결정경계를 가진 모델일수록 높은 variance를 가짐
ex. ANN - variance가 높은 모델은 오버피팅이 일어날 가능성이 높음
- 데이터가 조금만 변해도 민감하게 변화한다 -> 높은 variance를 보이는 모델
(3) Bias & Variance 관계
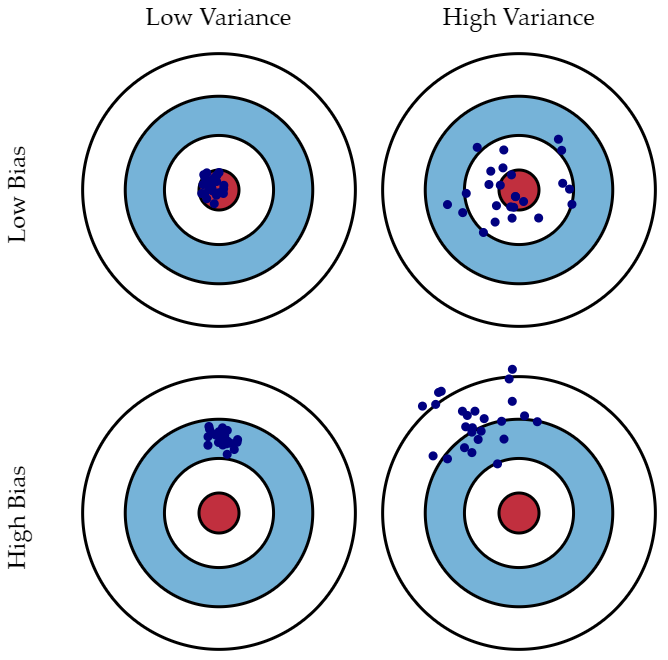
(4) 앙상블에서 사용
: " High Variance & Low Bias "
- 훈련세트의 작은 변화에도 다른 예측을 초래할 수 있기 때문에
각 base classifier은 오버피팅되기 쉬움 - 하지만 여러개의 base classifier을 사용하기 때문에 전체 variance를 줄일 수 있는 것
- 여러 개의 결과를 모아서 다수결을 통해 채택할거니까 여기서의 오버피팅은 상관없음
- 오히려 오버피팅 되도록 (= 오히려 variance가 최대치를 찍도록)
3. 앙상블을 구성하는 방법 세 가지
1) training set을 조합 (data object를 조합)
: 랜덤하게 데이터를 샘플링해서 base classifier가 각각 다른 train data를 사용하여 모델 생성
ex. bagging, boosting
2) feature를 조합
: input feature의 서브셋을 선택 -> 각 base classifier마다 다른 조합의 feature 사용
ex. random forest
3) learning algorithm을 조합
: 같은 training data에 여러번 algorithm을 적용
= 모델의 하이퍼파라미터를 다르게 해서 모델을 다르게 만드는 것
ex. ANN (초기 가중치 등을 각각 다르게), Decision tree(분류기준 Gini, Entropy 그런걸 다르게)
4. 최종 결과 결정법
1) Simple majority voting
: 그냥 다수결
2) Weighted majority voting
: 각 모델마다의 가중치를 다르게 (가중치 = 정확도, 중요도 등등을 표현)
-> 각 모델의 가중치 * 모델의 결과
-> 전체 값 더해서 최종 결과 결정
728x90
'Data mining' 카테고리의 다른 글
| [데이터 마이닝] 연관 분석 (Association Analysis) - 기본 개념 (0) | 2023.07.30 |
|---|---|
| [데이터 마이닝] 자기조직화지도(Self-Organizing Map, SOM) - 기본 개념 (0) | 2023.07.01 |
| [데이터 마이닝] 앙상블(ensemble) - Random Forest / multi class (0) | 2023.06.18 |
| [데이터 마이닝] 앙상블(ensemble) - Bagging, Boosting (1) | 2023.06.18 |
| [데이터 마이닝] ANN (1) | 2023.06.18 |
'Data mining' Related Articles
more



